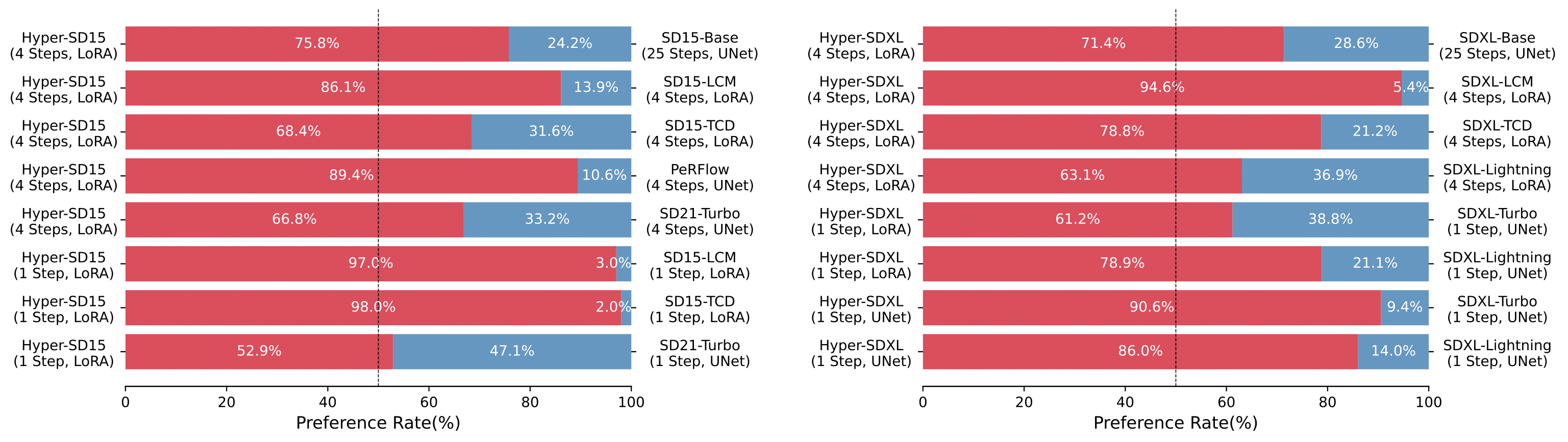
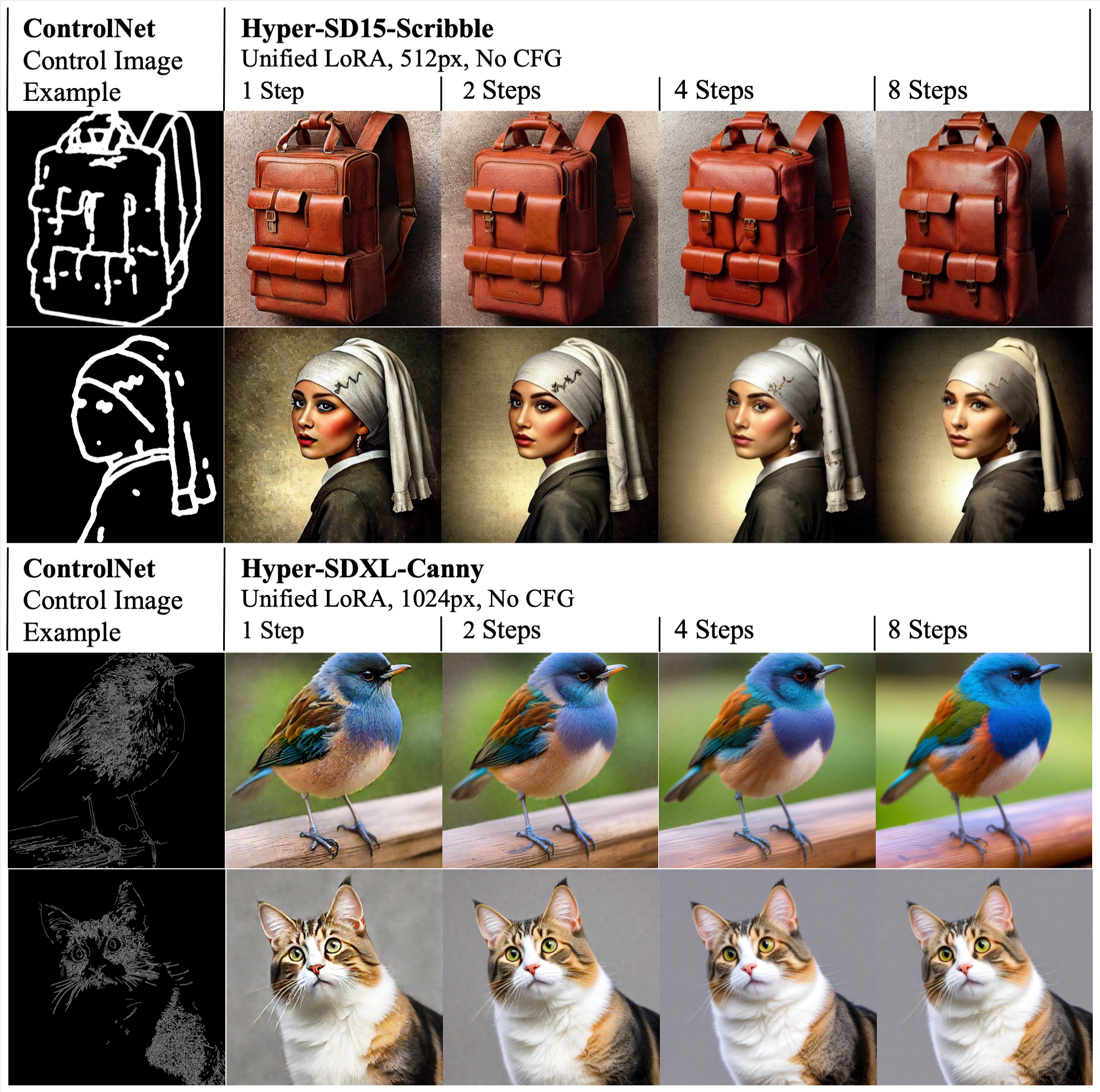
BibTeX
@misc{ren2024hypersd,
title={Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis},
author={Yuxi Ren and Xin Xia and Yanzuo Lu and Jiacheng Zhang and Jie Wu and Pan Xie and Xing Wang and Xuefeng Xiao},
year={2024},
eprint={2404.13686},
archivePrefix={arXiv},
primaryClass={cs.CV}
}